Silent Data Corruption (SDC) is an industry challenge affecting data centers worldwide with increasing frequency. This phenomenon stems from untraceable hardware failures that make detection notoriously difficult. SDCs don’t leave any record in system logs or trigger exception mechanisms. The corrupted data they produce can propagate unnoticed, causing cascading failures that often demand extensive resources to root cause.
A recent Open Compute Project (OCP) whitepaper, authored by experts from NVIDIA, Google, Meta, Microsoft, and others, underscores the critical impact of SDC on large-scale AI/ML systems.
OCP Says SDC Is on the Rise, Compromising AI Workload Integrity in Data Centers
SDC has emerged as a critical reliability threat to scaling AI training and inference, as it corrupts computations without triggering alerts. Unlike memory bit flips, for example, mitigated by error correction codes (ECC), SDCs originate from subtle timing violations, aging effects, or marginal defects that escape standard semiconductor testing and data center monitoring.
The problem has grown worse with GenAI's explosive growth and increasingly complex chip architectures, leading the paper to regard SDC as a "needle in a haystack" challenge. New process nodes push semiconductor boundaries, while the unprecedented scale of intensive AI workloads stresses chipsets to their thermal and timing limits.
The OCP paper walks through multiple stress factors that increase SDC probability in AI hardware, with several significant ones outlined below:

SDC Impact on AI Training and Inference
The OCP whitepaper emphasizes that SDCs pose distinct challenges depending on the type of AI workload. During training, even a single undetected fault can waste months of valuable computational resources by silently corrupting the learning process. In inference deployments, SDCs directly undermine the reliability of AI services by producing incorrect outputs. The impact is especially severe in safety-critical applications such as autonomous vehicles and medical diagnostics.
Workload-specific SDC impacts:
When SDC corrupts values without triggering Not-a-Number (NaN) errors, distributed training propagates this invalid data as legitimate results across multiple cluster accelerators. This contamination can lead to gradient explosion, implosion, or convergence at an incorrect local minimum. Such problems may take a very long time to detect while the training appears to be making forward progress.
Faulty hardware in inference clusters might generate corrupted outputs, potentially affecting thousands of users per hour. Debugging these errors can be highly challenging, as they can bypass detection mechanisms while compromising privacy and integrity policies. Moreover, this troubleshooting process can affect production capacity until the offending node is identified and quarantined.
Why Traditional Controls Miss SDC in AI Fleets
Standard testing methodologies, whether executed in situ or via scheduled maintenance, exhibit notable deficiencies:
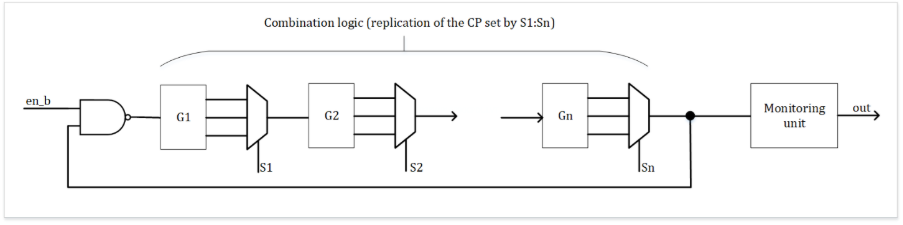
Given the limited efficacy of current best-known methods, the OCP paper dedicates a whole section to multiple open research questions. It regards SDC as an unresolved challenge with a critical impact on AI systems, calling for novel approaches that capture the nuanced ways in which silent errors occur.
proteanTecs’ In-Chip Monitoring Restores Trust With Real-Time SDC Prevention
Conventional SDC prevention methods typically rely on periodic maintenance, which incurs costly overhead by testing all servers regardless of their health. However, even fleet operators who accept the expense of excessive testing are not secure. Unfortunately, they still face many SDC cases, which they often detect only after the faults have already impacted the production environment.
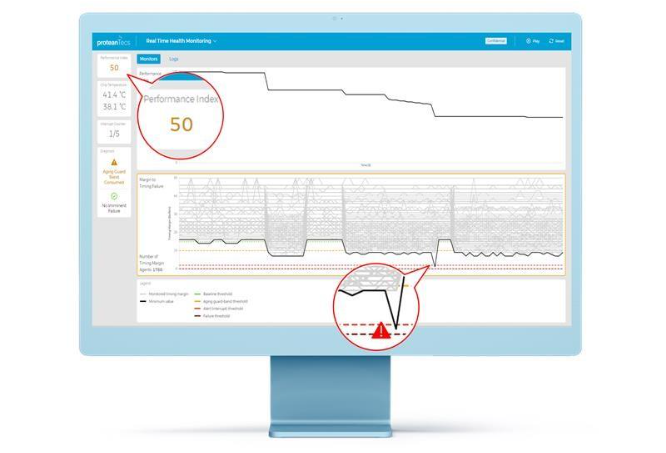
proteanTecs takes a different approach, offering predictive maintenance instead of preventive maintenance. This novel technology can identify issues in real time and even correct them. The detected events are not actual faults yet, but they might accumulate to a low chip Health Index, which often precedes SDCs. proteanTecs uses dedicated thresholds to deduce when margins get dangerously low, as depicted below.

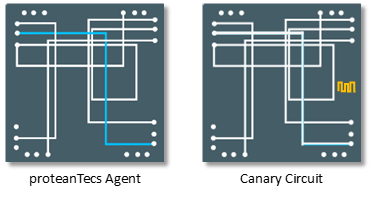
Unlike canary circuits, proteanTecs uses on-chip Agents that monitor the timing margins of millions of real paths for more informed decisions. These Agents can provide very high coverage of the design’s logic and pinpoint the real critical paths that traditional methods often miss. This approach allows precise action based on real workloads, aging, and IR drops.
proteanTecs provides the Health Index by processing on-chip Agent readings alongside other inputs using advanced real-time algorithms. A low index score might trigger an interrupt, allowing the Baseboard Management Controller (BMC) to decide whether to take corrective action given the current system status.
In some configurations, the proteanTecs solutions take corrective action on their own without the BMC, offering prescriptive maintenance as well. Chips equipped with this technology can automatically adjust voltage or frequency to compensate for aging, adapt to workload demands, and help prevent SDC.
Ensuring AI Reliability: Chip Monitoring as the Answer to SDC
As AI systems continue to scale and process nodes shrink further, SDC will only become more prevalent. The OCP whitepaper makes clear that traditional approaches to mitigating SDC are insufficient for the RAS (reliability, availability, serviceability) demands of modern AI infrastructure.
proteanTecs' runtime monitoring technology represents a fundamental shift in how the industry can address this challenge. By monitoring millions of real critical paths during actual workload execution, it transforms SDC from an invisible threat into a manageable risk.
The ability to detect margin degradation before it causes corruption protects months of training investment and prevents corrupted outputs from reaching inference customers. At AI's current scale and intensity, this capability is no longer optional.
